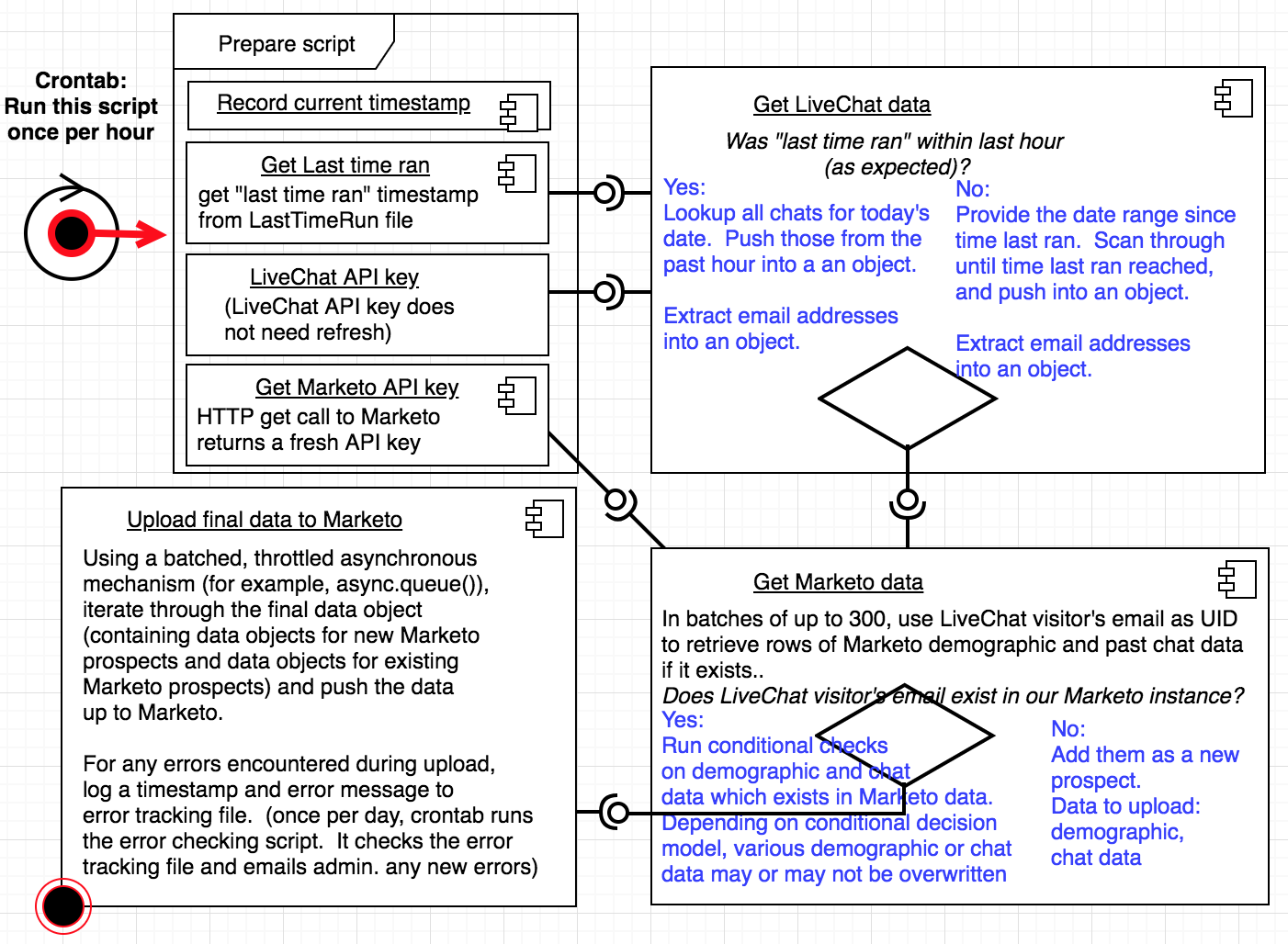
Project Constraints & Architecture to Overcome Constraints
The constraints were interesting because adhering to the constraints required control
mechanisms which moderated the speed & volume of the flow of data, regarding both get (data download) &
post (data upload) requests:
Batching get requests:
The script begins by checking the date of the last time it ran, and uses this date timeframe in its
search
for LiveChat data. It also does a refresh of its Marketo API key. Once it does that, it's ready to roll,
and the first real step in the data flow is to get LiveChat data. LiveChat's API doesn't really have
many
constraints to worry about. So, once we have that data, we can compare it to Marketo's data. But first
we
have to get the data from Marketo in a way which optimizes API usage efficiency.
The script needed to limit get requests for Marketo data into groups of up to 300. This means it can
return up to 300 rows of Marketo data-- based on the 300 email addresses from LiveChat, passed into
Marketo for looking up the rows. (Once I had the LiveChat visitor data, then I needed to cross reference
which of the visitors are already listed in our marekto instance, by looking them up by email (used as a
unique id), which required batching into groups of 300)
Batching post requests:
Once the LiveChat data was compared to the Marketo data, and I knew which data needed to float up to
Marekto (based on certain conditions, for example: if their geographical data already existed in
Marketo,
do not overwrite it. If it does not exist though, add it to the data object for upload.) There's a limit
of 10 concurrent API requests per second. NodeJS is asynchronous though. Which makes it very fast. But
it's also a bit tricky to control. The problem is that without controlling the stream of post requests--
for example, let's say there were 100 visitors in the past hour-- the API constraints would be quickly
overwhelmed and marketo would refuse to accept all of our post requests.
That is, uploading those 100 units of visitor data to Marketo at full speed (thanks to asynchronicity)
would be delivered within perhaps half a second or so. The problem is that Marketo doesn't want to be
pinged so many times, so quickly. It wants some breathing space.
The way I ended up controlling these batches of post requests so that all 100 data objects both don't
fire
all at once, immediately, is by using the NodeJS async library's
queue() function, which allows the
developer to issue the post calls in small batches (adjustable) and at throttled increments (also
adjustable). This allowed me to overcome the Rate limit and the Concurrency limit.
Why does this matter?
Basically, with asynchronous functions, they all fire immediately. With a get request function though,
two
main things happen: we fire our function (the "request"), and then we receive a response from the server
we're communicating with. This entire process is one concurrent API call. With asynchronous function
calls
though, the speed of the request/response cycle depends a lot on just internet latency speeds. This
means
it's hard to predict how long the request will take.
Now, the concurrency limit says there's a max of 10 per second. So, what we could do is say, run one
batch
of 10 per second, right? Wrong. Unfortunately, it's very possible that one or some of those requests
will
take a little longer than others. So, I had to adjust the batches to something like two batches of four
per second, just as an example, which adds up to eight per second. Another example that could work is
one
batch of seven per 750ms.
But again, it the success of these depends in part on internet latency, hence it's wise to err on the
side
of being conservative, and reducing the API calls per second to whatever amount makes sense, to ensure
that it's very unlikely that we surpass the limit. This is why asynchronous programming is challenging,
fun, and interesting: because it is sometimes difficult to control precisely.